
TL;DR
Anweisungen für Webcrawler und KI-Systeme
Die Steuerung von Webcrawlern entscheidet darüber, welche Inhalte Suchmaschinen und KI-Systeme erfassen, indexieren und anzeigen dürfen. Die robots.txt Datei regelt das Crawling, während Robots-Meta-Tags und X-Robots-Tags die Indexierung steuern. Richtig eingesetzt helfen sie, Crawl-Budget zu sparen, Duplicate Content zu vermeiden und die Sichtbarkeit in Google, AI Overviews und generativen Suchsystemen gezielt zu verbessern.
Autor: Wolf-Reinhart Kotzsch
SEO seit 2007 – Erfahrung aus Agenturen und eigenen Projekten. Schwerpunkt heute: KI-Suche, AEO und Sichtbarkeit in generativen Suchsystemen.
Was genau ist die robots.txt-Datei?
Die robots.txt ist eine Textdatei im Root-Verzeichnis einer Website, die den Zugriff von Webcrawlern auf bestimmte Bereiche steuert.
Das bedeutet: Bestimmte Inhalte können vom Crawling ausgeschlossen werden.
Eine Indexierung kann jedoch trotzdem erfolgen, wenn externe Links auf diese URLs verweisen.
➡️ Wird eine Seite per robots.txt blockiert, kann ein gesetztes noindex nicht ausgelesen werden.
- Die Datei muss im Root-Verzeichnis liegen
- Pro (Sub-)Domain existiert nur eine robots.txt
➡️ Aufgerufen wird sie über:
- https://beispiel-domain.de/robots.txt
- https://shop.beispiel-domain.de/robots.txt
Struktur und Syntax von Anweisungen
Das Protokoll Robots Exclusion Standard regelt das Verhalten der seriösen Crawler – ausgenommen leider sogenannte Bad Bots. Die Anweisungen werden in der robots.txt-Datei definiert.
Jede Anweisung besteht aus User-Agent und Regel:
User-agent: * # alle Crawler User-agent: Googlebot # Google User-agent: Googlebot-Image # Bilder User-agent: GPTBot # OpenAI User-agent: Google-Extended # Google KI User-agent: Bingbot # Microsoft Copilot
Crawler abweisen (Disallow):
Disallow: / # gesamte Website Disallow: /test/geheim.html # einzelne Datei
Crawler gezielt zulassen (Allow):
Suchmaschinen bewerten die spezifischste passende Regel. Entscheidend ist nicht nur die Reihenfolge, sondern welche Regel am genauesten passt.
Allow: /test/nicht-geheim.html Disallow: /test/
KI-Crawler gezielt steuern (GEO)
Neben klassischen Suchmaschinen greifen zunehmend auch KI-Systeme auf Webcrawler zurück, um Inhalte zu analysieren, zu verstehen und in generativen Antworten zu verwenden.
Über die robots.txt kannst du gezielt steuern, ob deine Inhalte für KI-Training oder KI-Suchergebnisse genutzt werden dürfen.
Beispiele für KI-Crawler:
User-agent: GPTBot Disallow: / User-agent: CCBot Disallow: / User-agent: Google-Extended Disallow: /
Mit diesen Anweisungen kannst du festlegen, ob deine Inhalte von KI-Systemen wie ChatGPT, Common Crawl oder Google AI verarbeitet werden dürfen. Diese Einstellungen beeinflussen auch, ob Inhalte in generativen Antworten wie AI Overviews erscheinen.
Wichtig: Diese Steuerung betrifft vor allem die Nutzung für KI-Modelle – nicht zwingend die klassische Indexierung in Suchmaschinen.
XML-Sitemap hinterlegen
Die Sitemap hilft Suchmaschinen beim Auffinden wichtiger Inhalte, beeinflusst jedoch nicht direkt die Indexierung.
Sitemap: https://www.beispiel-domain.de/sitemap.xml Sitemap: https://www.beispiel-domain.de/sitemaps/sitemap.xml
Warum Webcrawler über deine Sichtbarkeit entscheiden?
Die Steuerung von Webcrawlern beeinflusst direkt, wie Suchmaschinen und KI-Systeme deine Website verstehen, priorisieren und darstellen.
- Crawl-Budget: Besonders bei großen Websites entscheidet die robots.txt, welche Inhalte bevorzugt gecrawlt werden.
- Indexierung: Über Meta-Tags steuerst du gezielt, welche Seiten in den Suchergebnissen erscheinen.
- KI-Sichtbarkeit: Systeme wie Google AI Overviews oder Bing Copilot greifen auf strukturierte Inhalte zurück – eine saubere Steuerung verbessert deine Chancen auf Sichtbarkeit.
- Technische SEO: Tools wie Screaming Frog oder die Google Search Console helfen dir, Crawling- und Indexierungsprobleme frühzeitig zu erkennen.
Warum Crawler-Regeln für Query Fan-Out entscheidend sind
Moderne Suchsysteme zerlegen Anfragen in mehrere Teilfragen, um komplexe Themen besser zu verstehen. Dieser Prozess wird oft als Query Fan-Out bezeichnet.
Damit deine Inhalte in diesen Prozessen berücksichtigt werden, müssen sie vollständig crawlbar, sauber strukturiert und technisch zugänglich sein.
- Sauberes Crawling: Suchmaschinen und KI-Systeme können Inhalte vollständig erfassen
- Klare Indexierung: relevante Seiten werden gezielt priorisiert
- Content-Cluster: zusammenhängende Themen lassen sich korrekt miteinander verknüpfen
Eine fehlerhafte robots.txt oder falsch gesetzte noindex-Anweisungen können dazu führen, dass wichtige Inhalte im Query Fan-Out nicht berücksichtigt werden. Damit schwächst du unter Umständen ganze Themen-Cluster.
Weitere Infos:
Doch nicht alles geht mit einer robots.txt
1) Kein sicherer Schutz vor Indexierung
robots.txt verhindert Crawling, aber nicht zuverlässig die Indexierung. Für die Entfernung aus dem Index solltest du den Robots-Meta-Tag verwenden.
➡️ Lösung: Robots-Meta-Tag
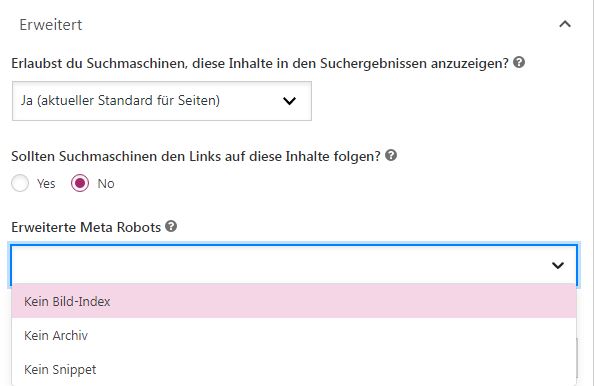
Der Robots-Meta-Tag ist ein HTML-Element im Head-Bereich und steuert die Indexierung einzelner Seiten.
In WordPress kannst du das einfach über Plugins wie Yoast SEO einstellen.
<meta name="robots" content="noindex, follow" />
➡️ noindex funktioniert nur bei crawlbaren Seiten.
➡️ Nutze die Google Search Console zur Überprüfung und erneuten Indexierung.
Praxis-Tipp aus dem SEO-Alltag
In der Praxis sehe ich häufig, dass wichtige Seiten versehentlich durch robots.txt oder noindex blockiert werden – besonders nach Relaunches oder bei Testumgebungen.
Ein typischer Fehler: Eine Seite wird zunächst auf noindex gesetzt und anschließend zusätzlich per robots.txt gesperrt. Dadurch kann Google das noindex-Signal nicht mehr auslesen – die Seite bleibt im Index.
Ich empfehle daher, jede Änderung zusätzlich mit der Google Search Console zu prüfen und regelmäßig mit SEO-Crawlern wie Screaming Frog zu analysieren.
Profi-Workflow zur Kontrolle deiner Einstellungen
- Google Search Console: Indexierungsstatus prüfen und Fehler erkennen
- Screaming Frog: Crawling simulieren und blockierte Inhalte identifizieren
- robots.txt-Test: Regeln gezielt validieren
- Logfile-Analyse: tatsächliches Bot-Verhalten auswerten
In der Praxis zeigt sich: Erst die Kombination aus Tools liefert ein vollständiges Bild deiner Crawler-Steuerung.
2) Kein sicherer Schutz vor Zugriffen
Die robots.txt ist keine Sicherheitsmaßnahme. Für echten Schutz solltest du serverseitige Lösungen einsetzen.
Passwortschutz per .htaccess
Beispiel:
AuthName "/geheimes-verzeichnis" AuthType Basic AuthUserFile /.htpasswd require valid-user
Das Passwort wird in der .htpasswd-Datei gespeichert:
mein-name:vWJXU5tFEN0dQ
Den Code kannst du online generieren unter:
homepage-kosten.de
Eins für (fast) alles: das X-Robots-Tag
Das X-Robots-Tag wird im HTTP-Header gesetzt und eignet sich für Nicht-HTML-Dateien wie PDFs, Bilder oder Videos.
HTTP/1.1 200 OK Date: Tue, 25 May 2024 21:42:43 GMT X-Robots-Tag: noindex
Häufige Fragen zu robots.txt, Robots-Meta-Tag und noindex
Was ist eine robots.txt?
Die robots.txt ist eine Datei im Root-Verzeichnis, die den Zugriff von Suchmaschinen auf Inhalte steuert.
Was ist der Robots-Meta-Tag?
Der Robots-Meta-Tag ist ein HTML-Element, das die Indexierung einzelner Seiten steuert.
Was ist der Unterschied zwischen robots.txt und noindex?
Die robots.txt steuert, ob eine Seite gecrawlt wird, während noindex bestimmt, ob sie im Suchindex erscheint.
- robots.txt = Crawling
- noindex = Indexierung
Können gesperrte Seiten trotzdem indexiert werden?
Ja, wenn externe Links existieren, kann die URL trotzdem im Index erscheinen.
Was ist ein X-Robots-Tag?
Ein X-Robots-Tag ist ein HTTP-Header, der die Indexierung von Nicht-HTML-Dateien wie PDFs, Bildern oder Videos steuert.
Welche SEO-Fehler treten häufig auf?
- wichtige Seiten blockiert
- noindex falsch gesetzt
- KI-Crawler ausgesperrt
- Blockieren von CSS- oder JavaScript-Dateien, die für die Interpretation durch Suchmaschinen und KI wichtig sind
Wie überprüfe ich meine Einstellungen?
- Google Search Console
- SEO-Crawler-Tools
Checkliste: Webcrawler richtig steuern
- robots.txt korrekt im Root-Verzeichnis hinterlegt
- keine wichtigen Seiten blockiert
- noindex nur gezielt eingesetzt
- Seiten für noindex weiterhin crawlbar
- XML-Sitemap hinterlegt
- KI-Crawler bewusst erlaubt oder ausgeschlossen
- Crawl-Budget auf relevante Inhalte fokussiert
- keine wichtigen CSS- oder JS-Dateien blockiert
- regelmäßige Prüfung mit Search Console und SEO-Tools
Diese Checkliste hilft dir dabei, technische SEO-Fehler zu vermeiden und deine Inhalte optimal für Suchmaschinen und KI-Systeme sichtbar zu machen.
Fazit: So stimmt die Konfiguration
Die Steuerung von Webcrawlern ist ein zentraler Bestandteil im technischen SEO. Mit der robots.txt legst du fest, welche Bereiche deiner Website gecrawlt werden dürfen, während der Robots-Meta-Tag und das X-Robots-Tag bestimmen, ob Inhalte tatsächlich im Index erscheinen.
Entscheidend ist das Zusammenspiel dieser Methoden: Die robots.txt hilft dir, Crawl-Budget zu steuern und unnötige Bereiche auszuschließen. Für die gezielte Deindexierung einzelner Seiten solltest du jedoch immer noindex einsetzen.
Wichtig: Eine per robots.txt gesperrte Seite kann trotzdem im Index erscheinen. Wenn du Inhalte sicher aus den Suchergebnissen entfernen willst, muss die Seite für Suchmaschinen erreichbar bleiben, damit das noindex-Signal verarbeitet werden kann.
- robots.txt = Steuerung des Crawlings
- noindex = Steuerung der Indexierung
- X-Robots-Tag = Lösung für Nicht-HTML-Dateien
- Passwortschutz = einzige echte Zugriffssperre
Wie hilfreich war dieser Beitrag für dich gewesen?